.svg)


This article explains how AI is radically changing SaaS unit economics, shifting from the old zero-marginal-cost model to token-based, variable expenses that can erode margins if left unchecked. This guide will give you pricing and budgeting strategies that will help you capture the benefits that building AI into your product can have for your business while managing cost volatility.
SaaS businesses have always created a kind of “margin magic”—build the product once and watch the margins grow. As customer acquisition costs get amortized over years and the costs to serve new customers goes down, eventually, the revenue from each new customer turns into pure profit.
However, that was then, and this is now. SaaS companies serving nearly every industry today are building AI into their products at break-neck speed and quickly discovering the challenges of maintaining their margins requires a paradigm shift in how they think about their unit economics.
AI SaaS companies (those leveraging LLMs to provide AI-powered features in their products) need an approach similar to that of manufacturers, where COGS takes center stage. Every customer query and product feature powered by an LLM costs money, which means CFOs now need to factor in token-based charges that accumulate with every API call.
These token-driven costs can erode margins without active management. The new variable SaaS cost structure and volatile margins require a new playbook. You’ll find that in this guide.
Why traditional SaaS economics no longer apply to companies offering AI-powered features
Traditional SaaS products provide enviable gross margins and scalable unit economics. However, this is changing fast for companies offering AI capabilities in their products. Every prompt and response consumes tokens that map directly to compute, which is a metered input you pay to LLM providers for based on usage. This means your COGS increases as users use AI features in your SaaS.
This new, per-token reality changes the unit economics of SaaS in three important ways:
- COGS is usage-linked, not user-linked: Instead of the cost being largely fixed once a seat is provisioned, inference spend rises with prompt length, response length, and concurrency. Even with caching/discounts, the marginal cost of the next request is not zero.
- Gross margins compress: AI application margins are often well below the 60–80% benchmark for traditional SaaS. This is especially true at a smaller scale or with heavy model calls embedded in core workflows.
- Cost volatility is higher: Model choice, context window, prompt engineering, and hardware availability all introduce volatility to your costs. This means unit costs can swing as vendors reprice or as you switch between GPU/TPU backends.
The new cost drivers every SaaS CFO must track
Two accounts on the same plan can generate dramatically different costs to serve because each user engages with the feature set with varying intensity. Each prompt (or token) processed has a direct impact on cost. And this impact varies by model as well as context and output length.
To track costs effectively, you need to monitor your recurring AI cost drivers.
Token and inference costs
Token and inference costs are visible, usage-indexed expenses. The primary token and inference cost drivers to monitor include:
- Per-token API charges for inputs and outputs: These often have different rates per direction and per model. For example, OpenAI’s GPT-5 is priced at $1.25 USD per one million input tokens and $10.00 USD per one million output tokens. These prices change frequently, so it’s important to check OpenAI’s pricing page for the latest rates. Regardless of the LLM you’re using, keeping an eye on pricing is key to optimizing costs.
- Consumption variability per user and workflow: Heavy users, long prompts, multi-turn agents, and complex prompts create a fat-tailed usage distribution that can compress your margins if your pricing isn’t aligned. Monitoring these patterns will help you know when and how you might need to revisit your pricing strategy.
The model you choose can also help you control costs. Some model providers proactively help SaaS companies tackle the challenges that introducing AI into their products creates. For example, OpenAI offers a pay-as-you-go option and lets you place caps and set up alerts to reduce bad debt and protect margin. Many providers now offer this pricing model because it balances frictionless access with cost control.
Hidden infrastructure and compliance costs
Beyond tokens, there are several infrastructure and compliance costs that are easy to underestimate. Here are some other costs to consider:
- Data storage: Storing embeddings, vector indexes, and historical logs for retrieval augmentation generation (RAG) can exceed the raw cost of tokens themselves. Every customer interaction increases storage needs, so make sure your pricing accounts for the lifecycle costs of your entire data pipeline, not just inference costs.
- Security and privacy controls: Token metering is only part of the story. Every incremental request may require secure logging, audit trails, and cross-cloud compliance overhead that add to your per-user cost.
- Regulatory compliance: Ongoing audits and compliance with privacy laws and other regulatory requirements can heavily impact a SaaS company’s cost structure, especially in low-scale or highly-regulated industries. For these companies, compliance overheads are often as high as compute costs, which forces CFOs to start treating them like a first-order cost driver instead of a support function.
- Model retraining and lifecycle updates: If you’re leveraging a foundational LLM that you’ve fine-tuned with your own data, your token costs don’t stop after you launch the model. You’ll need to plan for the expenses of additional training as the foundational model ages or if you change vendors. Each update requires fresh data prep, testing, and validation, which means ongoing expenses that eat into margins unless you proactively manage AI infra costs.
How token-based pricing is reshaping SaaS margins
AI makes margins a lot more volatile because usage growth adds margin pressure. Let’s look at how your margins could be at risk and the impact of cost volatility on your financial planning.
Understanding margin compression risk
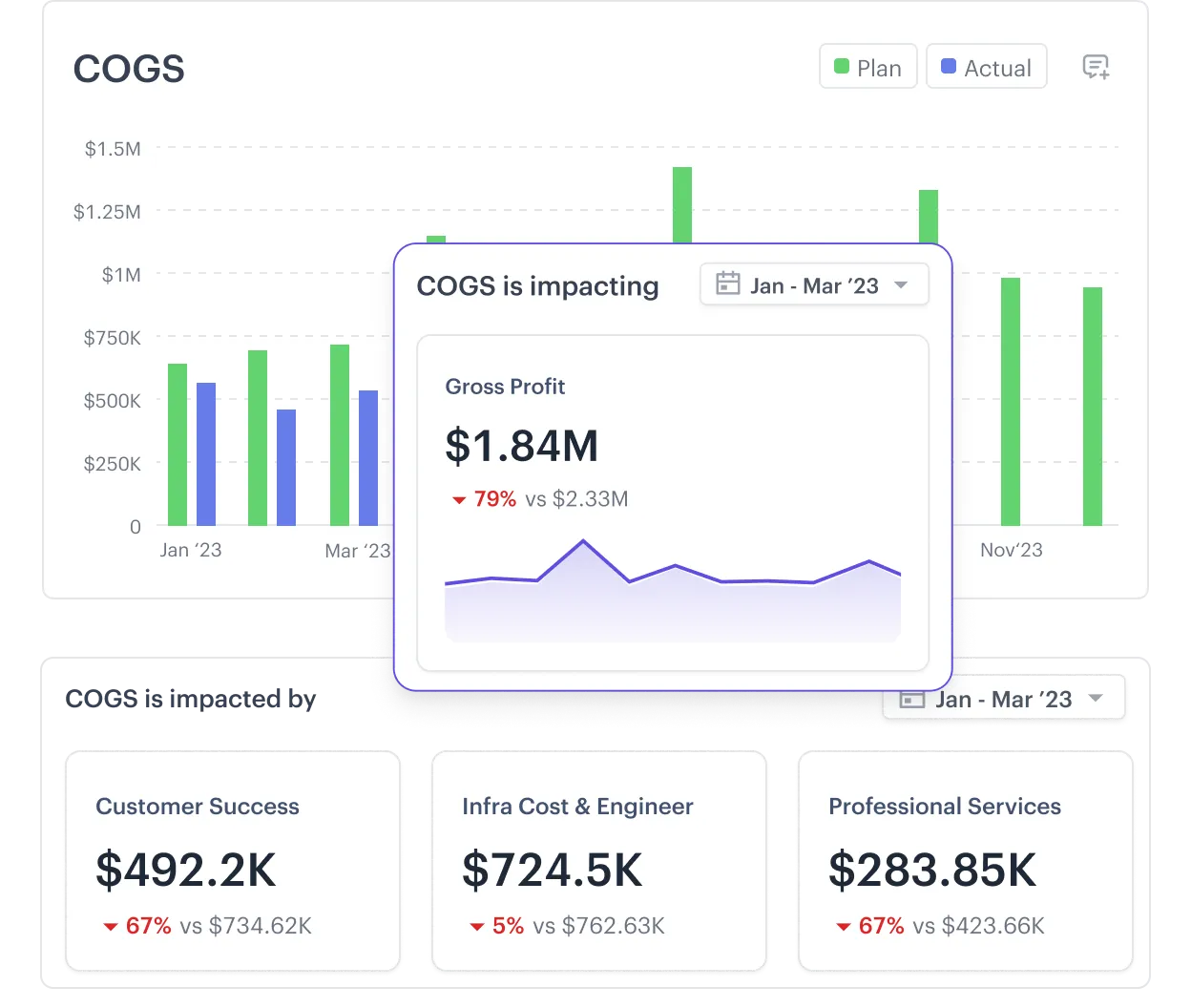
Your gross margin shrinks when customers ramp up their use of features that require more tokens. To protect margins, your product pricing needs to match usage.
For example, suppose a SaaS feature generates $100 in revenue and incurs $25 in direct token and infrastructure costs at moderate usage. If a subset of power users suddenly increases their prompt size or frequency, token costs could jump to $40 on the same $100 revenue.
This equates to an abrupt drop in your gross margin from 75% to 60%—something current and potential investors are sure to notice.
The impact of cost volatility on financial planning
AI SaaS companies have passed into a whole new frontier in financial planning, too, where cost volatility makes gross margin a moving target. In this new reality, a single enterprise client experimenting with long-form queries can deal a massive blow to your margins.
Some competitors might deliberately keep their prices low, even if it hurts their profit margins, just to acquire your customers and expand market share. This makes pricing even more challenging than it already is given new AI-driven competitive pressure to keep prices low.
Given these challenges, it’s not surprising that the non-static margin profile makes SaaS CFOs uncomfortable. But the best way to deal with uncertainty is to build a flexible financial plan that’s purpose-built to navigate this volatility.
Forecasting and budgeting for variable AI costs
Budgeting by averages doesn’t work for AI SaaS companies because it doesn’t factor in massive cost swings from spikes in usage. You need a flexible forecast and budget informed by multiple scenarios, including a worst-case scenario that includes massive increases in inference expenses.
Building flexible budget models
There are several frameworks you can lean on to manage cost variability. Each framework comes with trade-offs in predictability, flexibility, and complexity.
Prepaid consumption models
Your finance team allocates a fixed budget of prepaid credits (or “token allowances”) that cap runaway costs. Vendors like OpenAI already use this method to manage enterprise usage.
Prepaid consumption models offer more predictability and protect your gross margins to an extent. But they also restrict product adoption if caps are hit early.
This model works best for early-stage SaaS companies that want to encourage experimentation while keeping costs under control.
Rolling or variable budgets
Teams use rolling forecasts updated quarterly or monthly instead of setting an annual budget, treating AI usage as a variable expense. The budget is then adjusted continuously based on actual usage data.
While this model offers more flexibility and better reflects real consumption, it increases your workload and requires a strong tracking and reporting infrastructure.
If you’re a growth-stage SaaS with fast-changing adoption patterns and evolving product-market fit, this model may be the best approach for you. If tracking actual cost and usage data seems daunting, you can always use a tool like Drivetrain to consolidate data from your source systems (e.g., usage data from your LLM providers) to unify and automate reporting.
Models anchored on unit economics
With this model, budgeting is tied to “cost per workflow.” Tokens are considered an input to the unit cost, not the unit itself. To implement this, you need to trace token usage through to revenue-generating units (such as cost per user query, report, or workflow). So, instead of managing costs at the token level, you can manage them at the contribution level.
When you budget with unit economics in mind, you connect your budget to value-creating activities that customers do inside your product. For example, instead of saying, “We spent $30,000 on tokens last month,” you’d say, “It costs us $0.07 in tokens + infra every time a customer runs a compliance report.”
The only challenge is that this method requires careful instrumentation and ongoing updates as usage patterns evolve. mature AI SaaS companies with measurable workflows, stable usage patterns, and pricing leverage and where CFOs want clarity on true contribution margin.
Scenario planning for different growth trajectories
Scenario planning is critical to managing inference and other AI-related expenses because it helps you stress-test your budget under different AI usage scenarios.
If you play your cards right, scenario planning can help you balance ambition with financial prudence. It can also give leaders the confidence that margins won’t implode if growth or costs don’t go according to the original forecast.
Let’s look at some scenarios for various growth trajectories and the risks you need to be aware of with each one.
Conservative adoption scenario
A conservative forecast assumes your customers will try out your AI features, but not heavily leverage them. They’ll run a limited number of prompts, and most of them will be short and inexpensive.
This conservative scenario is quite common for SaaS companies with premium-priced AI add-ons that aren’t yet widely adopted.
In this scenario, you expect limited downside exposure, so you avoid overcommitting to infrastructure or retraining in your forecast. But it can also understate real costs if adoption accelerates quickly.
Aggressive growth scenario
An aggressive forecast assumes rapid adoption of AI features, which means longer and more complex prompts, and higher concurrency, all of which collectively result in dramatically higher token usage.
If you offer AI as part of your core product, where usage will likely scale with the customer base, this scenario might be an actual reflection of your reality. It helps you prepare for “success risk,” where high adoption drives up costs faster than revenue.
Of course, it’s also possible that you overestimate costs and price too conservatively with this assumption.
Competitive pricing pressure scenario
Under this scenario, you assume that rivals drop their AI feature prices or bundle them in, forcing everyone to operate with slimmer margins while costs stay volatile. This is often the case with companies in crowded markets where pricing wars are common.
This is your worst-case scenario from a gross margin perspective, assuming cost structure remains unchanged.
However, it may be overly pessimistic unless you use it with some realism—are your competitors really willing to erode their margins by pushing price downward? And can they sustain that pricing for the long term?
Vendor cost-shift scenario
This model assumes that model providers may change token pricing, introduce new context windows, or change billing rules halfway through the year. Almost all AI SaaS companies are exposed to this risk because they depend on LLM providers like OpenAI or Anthropic.
Planning for this scenario makes your budget more resilient by acknowledging that some cost drivers are outside your control.
Unfortunately, it’s harder to plan for a change in the provider’s pricing for exactly the same reason—it’s outside your control. You could look at the pricing history with the LLM providers you’re using and assign probabilities based on that. However, that history is arguably pretty short, so you may be forced to simply make some assumptions here.
Pricing strategies that protect margins while scaling AI features
Pricing isn’t just about how much people will pay for your product. It’s also a shield that protects your gross margins.
This irony for AI SaaS companies is that the very metric that once guaranteed success—user growth—now demands a careful balance between scaling revenue and managing the growing appetite of users for the AI features in their products.
Finding the right balance here is critical for protecting your margins. You need a pricing strategy that aligns customer consumption with AI costs, one that allows you to leverage AI to grow your business while also insulating you from runaway expenses.
Hybrid pricing models (base + usage)
The hybrid pricing model combines stability with flexibility. You charge a fixed-base subscription that guarantees predictable recurring revenue and a usage-based component that ensures AI consumption costs are covered.
The tricky part is in the calibration. If the base fee is too low, you risk underpricing high-value customers who drive up your AI costs. On the other hand, a high base fee scares off low-usage customers.
The best way to hit the sweet spot is to anchor the base fee to the value of your core product (non-AI functionality) and use the usage-based element to offset variable AI costs like API calls and inference. This way, customers enjoy predictable billing while you protect margins against cost spikes.
Pure usage-based pricing
This is a standard usage-based pricing model where customers pay strictly in proportion to their AI consumption (tokens processed, queries run, etc.). This aligns costs and revenue closely, but volatility can make revenue forecasting a bit tricky and can result in customers being frustrated when their bills increase dramatically.
That’s why this model is best for developer tools, APIs, or products where customers inherently understand metered pricing and want granular control over spend. However, even for these types of customers, it’s important to be very clear in your pricing policies regarding how the use of specific AI features can impact their costs.
Tiered packaging with AI quotas
Here, think “good, better, best” plans, where each tier includes a bundle of AI usage, say 10k queries/month. Exceeding this quota triggers overage fees or an upgrade to the next tier.
This strategy protects margins by making heavy users pay more while giving customers a clear framework for understanding value.
Tiered pricing works best for B2B SaaS, where procurement teams prefer fixed plans but scalability isn’t capped, which means revenue grows as usage grows.
Feature-gated AI add-ons
This strategy involves packing AI features as a premium add-on separate from the core subscription.
This keeps base pricing attractive while protecting your margins by monetizing AI-heavy functionality only for customers who need it. It’s an excellent option for SaaS platforms where AI is optional or where adoption is still nascent.
Value-based pricing tied to business outcomes
Under a value-based pricing strategy, you would price your AI features according to the business impact for the customer instead of charging by tokens or usage. This model disconnects pricing from raw AI costs but maximizes willingness to pay.
Examples of “value” might include the percentage of revenue recovered (from fraud detection) or cost savings (from workflow automation).
It’s important to note here that while this model could be powerful, it’s still largely theoretical. This is because proving ROI to justify value pricing requires detailed analytics capable of connecting model usage to quantifiable customer business results—something that would be highly complex to set up, let alone manage at scale.
A framework for CFOs to build financial controls and cost observability for AI
Keeping AI costs on a leash isn’t always simple because AI spend is both variable and opaque. Building financial controls and tracking costs isn’t just a best practice; it’s critical to survival in the Era of AI.
Implementing cost governance and controls
Here’s a three-phase framework, adapted for CFOs to help you deal with the complexity of AI costs:
1. Collaborate with your engineering team
Understanding AI spend at a granular level is critical to controlling and optimizing it. Work with your engineering team to identify all the different costs that need to be factored in, including the different AI models you’re using, the typical workloads and usage patterns for each, and if possible, by customer segments.
These conversations will help you and your engineering team see costs more clearly and can catalyze new ideas to help you manage them more effectively.
2. Optimize
With the information you get from your engineering team, you’ll understand your AI cost drivers and where there may be redundancy or waste you can eliminate. You’ll also be better able to make informed decisions about what levers you might need to use to optimize your spending, which might include:
- Optimizing GPU usage
- Fine-tuning your built-in prompts
- Negotiating commitment discounts
- Shifting volume to cheaper models based on demand
3. Control spend (to the extent possible):
Adding guardrails and cost awareness to workflows is a good start, and working with your engineering team will help you figure out where and how to do that strategically.
Setting budgets and thresholds for different models, workflows, and/or customer segments, with automated alerts, can also help prevent runaway usage before it starts hitting your profitability.
Tools and technologies for AI cost management
While it’s easy enough to work with your engineering team to get a more detailed understanding of your AI spend, putting that information to work for you requires a consistent stream of accurate data. The right technology makes this possible. Here are some systems you need in your toolkit to manage AI costs:
- AI-specific cost dashboards: Several platforms on the market focus on providing AI SaaS companies token-level visibility and real-time cost tracking across LLM providers, including usage breakdowns by user/team, built-in budget limits, and alerts.
- Anomaly detection and real-time alerting tools: Some platforms can use AI to spot cost spikes in real time, find the root cause, and instantly notify users. Using such tools can help keep unexpected computer costs under control.
- FinOps and cloud cost management platforms: These tools range from specialized infrastructure monitoring (GPU usage, vector databases) to comprehensive enterprise governance platforms providing cost allocation, multi-cloud budgeting, and policy enforcement across AI workflows.
In addition to these tools, you’ll need a comprehensive financial planning and analysis (FP&A) solution. Effectively managing your AI costs is daunting enough without the added work of tracking all the critical inputs across several different source systems.
Given the high volatility in usage and the need for agility in response to rapid change, CFOs need a system that can automatically consolidate data from every platform they’re using to track their AI spend into a single, unified view—one that they can rely on to monitor changes in real-time and know how to respond effectively.
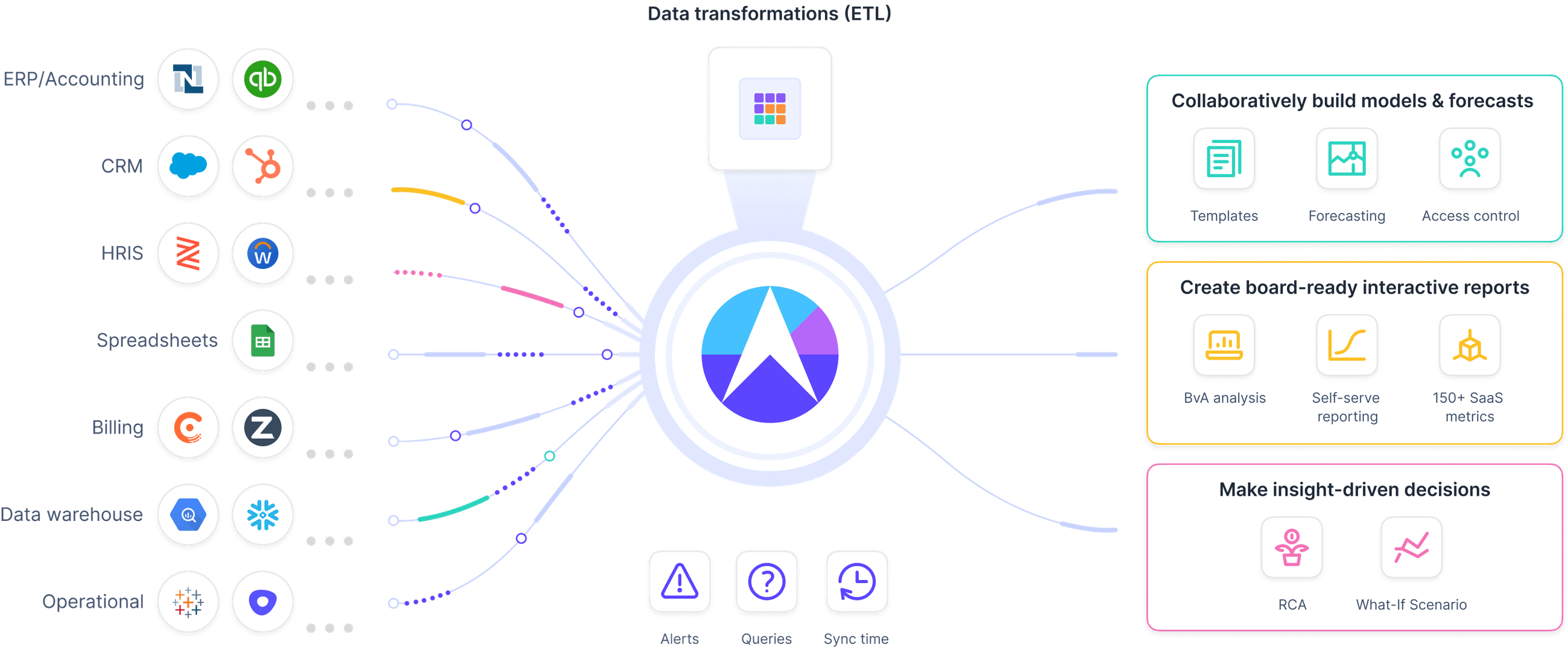
Smart CFOs today are turning to Drivetrain because it provides everything they need:
- 800+ native integrations: You can easily connect Drivetrain with every source system you use to monitor all the different drivers of AI spend in real time.
- Custom metrics: Develop custom metrics that accurately reflect AI usage metrics and other AI cost drivers to track their impact on revenue and margins and embed them in your forecasting models.
- Dynamic dashboards: Create custom dashboards that combine your custom metrics and those you pull in from integrated data sources to provide deep visibility into your AI costs.
- Unlimited scenario planning: Explore different pricing models, including usage-based pricing, and leverage “what-if” analysis to prepare for more specific possibilities, such as usage spikes in different customer segments or unexpected cost increases from LLM providers.
Are you struggling to manage your AI costs? Reeling from an abrupt and painful drop in your margin? Drivetrain can help. As an AI-native company ourselves, we can show you how you can gain full visibility into your AI spend for better control and strategically optimize it to protect your margin.
Frequently asked questions
Forecasting AI costs with perfect accuracy is impossible, but you can still get directional control. Here are some things you can do to get your forecast closer to reality:
- Model costs around key drivers like API calls and GPU hours. Then layer in scenario planning.
- Use rolling forecasts instead of annual ones so you can course-correct monthly or quarterly.
- Tag and allocate costs to specific features of customers to see what’s driving AI spend.
It’s hard to find reliable benchmarks for AI SaaS unit economics, but there are some useful reference points:
- In 2020, a16z reported that AI SaaS companies were commonly operating with much gross margins of 50-60% as opposed to the 60-80% common for traditional SaaS businesses at that time. This gap has likely grown with the rapidly increasing use of AI and the resulting volatility in inference and compute costs.
- In 2023, Tom Tunguz noted the extreme difference in cost between proprietary vs. open source models. He estimated the cost of a 500-word GPT-4 response used to cost about $0.084, whereas open-source alternatives like Llama 2 reduced that cost to as little as $0.0007 for the same output, making proprietary models over 100x more expensive.
- Based on findings in a 2024 study by Boston Consulting Group (BCG), unit economics can vary significantly across LLMs, user profiles, and time. The data suggests that if your customer journey includes multiple such interactions, a rough benchmark might be a few cents per journey for lightweight workflows but could climb to tens of cents, depending on model complexity and response length.
Direct pass-through charges may trigger pushback from customers. A hybrid pricing strategy with tiers (like “Pro” plans with premium AI features) or transparent-usage pricing tiers, where customers clearly see the cost-to-value tradeoff, may be a better approach.
Set budgets, alerts, and guardrails. Use cost-allocation tagging (by team, project, or model), so you know who’s driving spend. Apply rate limits or quotas to prevent runaway usage and review model selection. Cheaper models often deliver sufficient accuracy. Establish a weekly or monthly cadence to track burn rates and spot anomalies. The goal is to prevent any surprise bills and zombie workloads.
Pitch AI spend like cloud and R&D costs—variable but tied to growth. Translate spend into cost per customer, query, workflow, or other unit economics instead of just raw compute. At the same time, show how you plan to control volatility with budgets, usage caps, and model choices, and link spend to outcomes like faster product cycles, customer retention, or revenue gains.




.webp)



