.svg)


AI infrastructure spend can be difficult to deal with because it’s volatile and hard to predict. Usage-based AI models can spike costs unexpectedly. While this isn’t an entirely new territory for companies with usage-based pricing, it’s a budgeting headache for most SaaS businesses. In this article, we show how to forecast and manage AI costs and make the process a lot less intimidating.
There’s a new vendor in town. Actually, several. And they all want a cut of your revenue.
If you’re an AI-native SaaS company or offer AI-powered features, you’re now contending with a new class of vendor and a new kind of variable cost, one that’s tough to predict and even tougher to manage, especially under a usage-based pricing model.
SaaS teams are used to wrangling cloud spend. Sure, it’s variable, but it usually scales with the customer base. Even with usage-based pricing, you can lean on historical patterns to forecast costs with some confidence.
But AI spend is a different beast. You now have to predict your customers’ AI consumption instead of just your product in general. This requires accounting for the cost of inference calls and other usage-based fees your model provider charges—fees you may not have anticipated when you were initially evaluating usage-based pricing models.
And unlike cloud spend, AI usage doesn’t correlate cleanly with overall product usage. Some customers go all-in on AI, hitting every feature you’ve built, while others barely touch them, even if they’re high-volume users.
There’s a lot to unravel, so if you’re interested in learning the best way to manage AI spend for your SaaS product, jump right in.
Understanding AI-related costs in SaaS
AI costs in SaaS don’t follow the typical playbook. There are no “per seat” or “monthly flat fee” models. Instead, they work like cloud infrastructure costs, where usage (called compute in the context of AI) drives spend.
GPU time is the biggest cost driver for AI-native SaaS products. GPU costs are wrapped into the token-based pricing that model providers charge. A “token” is a chunk of text (roughly four characters), and both your inputs and the model’s outputs count toward your total token usage. The more tokens you use, the more GPU time you consume, and the more it costs you.
Some providers share a “model card,” which outlines the architecture, training data, hardware requirements, and performance benchmarks of the model. They can help estimate GPU intensity and choose the right model for your budget and performance requirements.
You might also see a few hidden costs when the bill arrives for your AI model usage. Some typical hidden costs to watch out for include:
- Background usage: Some models continue processing even after the user interaction is complete if you’ve integrated streaming or real-time responses. That extra compute time increases the cost.
- Prompt bloat: Bigger, more complex prompts use more tokens. This drives up the price. So if you don’t optimize prompts, you end up overspending.
- Multiple environments: If you’re testing across staging, QA, and production environments, you might be running the same workload multiple times, increasing your total costs.
- Idle compute or over-provisioned resources: If your GPU instances aren’t being fully used, just like your cloud infrastructure, you end up paying for unused capacity.
In addition to your AI model, there’s a growing market of third-party services. If you use them, you’ll also need to factor their pricing into your AI infrastructure costs. Here are examples of services available in the market:
- Fine-tuning and inference services: These services help companies customize existing AI models using their own data (fine-tuning) or run experiments to see how the models perform (inference testing). These tools are helpful if you’re building something tailored, but they get expensive pretty quickly, especially if you’re running lots of tests or using large models.
- LLM observability tools: These tools track and monitor how much you’re using AI models and how much it’s costing you. They’re like an analytics dashboard for your AI spend. They help identify things that increase costs, like inefficient prompts or unexpected usage spikes.
- Offer supporting tools and platforms: Several vendors help with prompt engineering platforms, vector databases, and model orchestration. While each tool may not be expensive individually, they can add up if you deploy multiple tools simultaneously.
Finding and tracking AI-related costs in your product
AI-related costs pop up in various areas. Some are obvious; others, not so much. Here’s why finding and tracking AI-related costs isn’t straightforward:
- You’re charged for every user interaction, typically priced by token usage.
- Some features may need special models (like reasoning models for logical tasks), which are more expensive.
- Your costs can change depending on how much users interact with the model and how efficiently you’ve written your prompts.
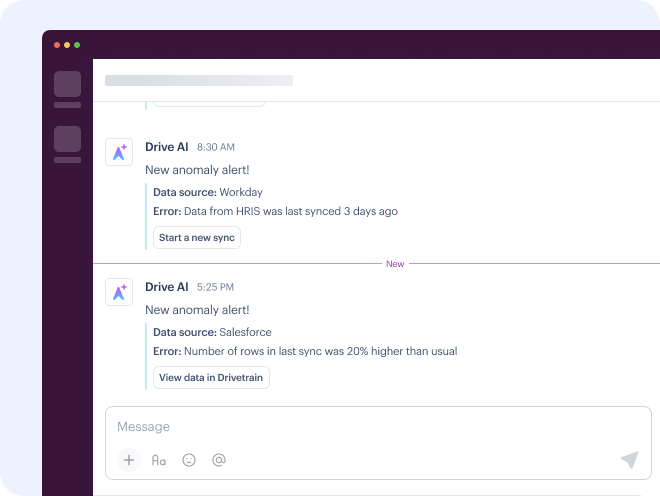
Suppose you’ve set up anomaly alerts in your product. The more alerts your users generate, the more interactions you’ll see, which means higher usage and more costs. To track these costs, you’ll need to monitor how often anomalies are triggered and where the model might be over-firing or underperforming.
There’s another problem to deal with: choosing the right model is an ongoing process.
You’ll want to test various models to see how they perform when used for the feature you’re building. And you’ll want to do this frequently because AI is evolving fast. A model that was top-notch two months ago might be outdated for your use case today.
You can track costs even with all of these challenges using several tools:
- LLM providers (like OpenAI or Anthropic): Your provider might offer dashboards or itemized usage reports that break down costs by model, endpoint, or even user session.
- LLM observability platforms: These platforms monitor how users interact with models and track usage down to the token level. They help you identify which users and features are major cost drivers.
- Your own backend: Your company data can also provide insight, provided you’re logging it properly. You’ll likely need to log this data anyway to evaluate model performance, so it makes sense to use that data for tracking usage and cost as well.
GPU costs
As you track your spend, you’ll notice that most costs are ultimately GPU costs. Whether you pay for them directly or indirectly through an AI provider is a different question.
GPU-related costs can be categorized into three main buckets:
- Training: Building a model from scratch.
- Fine-tuning: Customizing a pre-trained model with your own data.
- Inference: Running the model to respond to user queries.
Whether you see GPU costs on your invoice or not, you're paying for them, regardless of which bucket your use falls into. Here’s how you might be paying for GPUs:
- When you use an off-the-shelf LLM, the inference cost is built into the token price.
- If you’re fine-tuning the model for your product (which many companies do), you’re paying for GPU time by renting resources from an LLM cloud provider.
- For companies that purchase their own GPUs, costs depend on how efficiently they use them. Idle GPU time is just wasted money and increases the time required to generate a return on the GPU investment.
How to forecast and budget for AI spend
The simple answer: by estimating the tokens you expect your SaaS customers to consume for each AI-powered feature and multiplying it by the LLM provider’s price per token.
As a CFO, forecasting is part of your core skill set. But how do you forecast and budget for AI spend when you have no data to estimate token usage? Here’s what you can do to build a reliable forecast:
- Benchmark early pilot usage.
- Model expected usage growth per user or feature.
- Build scenario forecasts (such as for moderate vs. aggressive user growth).
Once you have a forecast for the total AI-related costs, break it down and allocate AI costs across features. To do this:
- Build visibility into the features that are driving token usage.
- Use tools or tagging systems to assign costs to feature areas or product lines.
- Let product and finance teams see exactly where the spend is coming from.
Allocating AI costs this way ensures product and finance teams have visibility over and can take ownership of cost efficiency.
How to manage your AI spend (and avoid getting blind-sided)
AI spend scales with usage, and it scales fast. You need to actively work on building systems that keep costs in check without hindering innovation.
Unfortunately, many SaaS companies take a reactive approach. When they notice infrastructure spend increasing faster than usage, they send engineers to optimize code and prompts. It works, but here’s a better way to handle AI spend:
- Set up usage and cost alerts: Set up alerts so your system notifies you whenever something unusual happens, like a spike in token usage or prompt failures. This will help you catch runaway costs early.
- Monitor AI intersections at the feature level: Track usage down to specific features and user flows. This will give you the context needed to optimize without jeopardizing key functionality.
- Create “cost per action” benchmarks: Estimate what one interaction should cost for each AI-powered feature and use that as a baseline to monitor for inefficiencies.
- Tighten the loop between engineering and finance: Don’t make your engineers guess what counts as expensive. Clearly define what efficiency looks like, and give your engineering team access to tools and alerts to make sure they don’t go over those limits.
The lightning-fast evolution of AI models complicates things further. Your unit economics today might look different six months from now. Costs might drop, or model performance might improve. To keep up, you need a dynamic approach to pricing and cost management. For example, this approach might include:
- Regular reviews of unit economics as models change.
- Flexibility in pricing structures (by usage tier, feature, and customer segment).
- Tools that make these variables visible (more on that in the next section).
Collaboration between technology and finance leaders
Managing AI infrastructure is a shared responsibility, with the CTO and CFO being key collaborators. As AI usage increases across your product, the line between engineering decisions and financial outcomes will start to blur.
That’s exactly why CTOs and CFOs need to work closely together to monitor usage and formulate the pricing strategy. Engineering takes charge of model complexity, inference frequency, and infrastructure, while finance monitors costs and ROI.
This is where technology comes in to make the job easier for both teams. A tool like Drivetrain can offer both teams a shared, real-time view of forecasts, budgets, and actual figures. By connecting AI-related cost drivers directly to financial models, both teams can collaborate on planning scenarios and evaluating trade-offs.
Thinking about cost optimization in a new way
“The traditional approach SaaS companies took in R&D to optimize cloud hosting costs doesn’t apply anymore, at least not completely. Back then, it was all about reducing compute, network, and storage. We did that by refactoring code, fixing the DB architecture, and so on. With LLMs, the concept of optimization now includes a complex token estimation puzzle.” – Tarkeshwar Thakur, Drivetrain Co-founder & CTO
AI infra is evolving fast. And staying on top of cost drivers, especially at a granular level, is mission-critical. The idea is not just to cut spend, but to understand its drivers, accurately forecast it, and adapt pricing models quickly.
Financial planning and analysis (FP&A) software like Drivetrain can be invaluable in helping AI-powered SaaS companies understand and optimize their LLM costs.
With more than 800 integrations, Drivetrain can connect to all of the systems you’re using to track AI-related usage and expenses to provide complete and comprehensive visibility into your AI spend. Drivetrain can consolidate usage data from LLM providers and/or third party observability platforms as well as any systems you may have built internally to help you manage it all.
So, instead of manually extracting the necessary data from each individual system to piece together that cost puzzle, you can spend your time understanding and optimizing instead.
Drivetrain’s automated data consolidation offers a lot of powerful benefits for managing your AI-related costs:
- With all your data in a single platform, you can see the full picture of your AI cost. This is particularly important with LLM costs due to their unpredictable nature, both in terms of your customers’ usage but also in LLM pricing. Models are improving quickly, which can also impact your costs, especially if your AI features require the most up-to-date LLMs. With everything in one place, you can quickly identify which cost drivers you need to focus on optimizing.
- You can optimize your AI-related spend proactively and in real time. With your data flowing into the platform in real time, you’re not going to get blind-sided with unexpected increases. Drivetrain is an AI-native company itself and offers AI-enabled anomaly alerts that notify you immediately when costs exceed the threshold you’ve set for them so you can investigate the issue before it drains your budget.
- Planning for AI-related costs becomes easier too. As a comprehensive FP&A platform, Drivetrain provides powerful scenario planning tools that you can use with your AI-related data to more reliably forecast your costs. You can also track your unit economics, like LLM cost by user or by action, which will provide the insights you need to make cost- and pricing-related decisions about the AI features you offer in your product.
Take some time today to explore all the ways Drivetrain can help you bring more predictable growth to your AI-powered business!
Frequently asked questions
Start by estimating your token usage and looking at your model’s pricing to get an idea of your AI spend. Then, set clear budget thresholds and implement show-back or charge-back models so teams have visibility over the cost impact of their experiments.
Review actuals against forecasts and see if there are major deviations from estimates. If there are, investigate further. At the same time, create a feedback loop between finance and engineering to course-correct quickly when usage spikes or assumptions change.
To forecast your AI spend, you first need to understand your use case and your users’ behavior. This helps you estimate token usage and inference frequency, which helps forecast AI spend. Then, you can further solidify your forecasts by using scenario planning to map out best-case and worst-case cost curves. Keep refining your forecasts with real usage data over time, and you’ll likely see your accuracy improve as you gather more actual data.
To allocate AI infrastructure costs, create dedicated line items like model training, inference, storage, and tooling in your budget so they don’t get lost in broad R&D or cloud buckets. Use observability and cost allocation tools to track usage at a granular level so you can tie these costs back to features and pricing decisions. Your first forecast won’t be perfect, but over time, forecasts will improve as usage patterns stabilize and you have more actual data.




.webp)



